




Table of Contents
Looking for the easiest ways to extract data from the website?
Web Scraping is the ideal solution for extracting data from the web. Indeed, another finest way to extract data from websites is API. However, web scraping makes the job easier and more ready for work. This is a beginner’s tutorial for performing web scraping using Python. Let’s understand what is Web scraping, the working and how to integrate it with Python.
Web scraping (Screen Scraping, Web Data Extraction, Web Harvesting )is an automated method to scrape a larger amount of data from the websites. Even copy and paste of the quote or lines which you like from the site are also the form of web scraping. Most sites won’t allow you to save a copy of the data from their websites for your use. So the only option was to manually copy the data and it consumes a lot of time, which might even take days to complete.
The data on the websites are mostly unstructured, here Web Scraping comes to the rescue. Web Scraping helps to scrap those unstructured data and store it in your own customized and structured form to the local machine or to the database. If you are scraping a web page for educational purposes then you are unlikely to have any problem but still, it is a good practice to do some Web Scraping to enhance your skills on your own without violating the terms of service.
Collecting data from different webpages can be difficult to manage. Web Scrapping can make your job easy if have written a web scraping script, then all you have to do is run the script to extract the data.
What is Web Scraping?
Web Scraping is a technique to extract any amount of data and get it saved to any local files on your computer. Using Web scraping you can also do Price Comparison, Job listings, Email address gathering, Social media scraping, Research, Development and more. But here we can just be going to extract data from a website.
Why Python for Web Scraping?
Python is incredibly fast and easier to do web scraping. Being too easy to code, you can use simple small codes to perform large tasks.
How Does Web Scraping work?
We need to run the code for web scraping so that a request is sent to the URL of the website that we wanted to scrape. The server sends the data and allows us to read the HTML or XML page as a response. The code parses the HTML or XML page, finds the data and extracts them.
Here are the steps to extract data using Web Scraping with Python
- Look for the URL that you want to scrape
- Analyze the website
- Find the data you want to extract
- Write the code
- Run the code and extract the data from the website
- Store the data in the required format in your computer
Libraries used for Web Scraping
The libraries you can use for web Scraping with Python
- Requests
- Beautiful Soup
- Pandas
- Tqdm
Requests is a module which allows you to send HTTP requests using Python. The HTTP request is used to return a Response object with all the response data such as encoding, status, content, etc
BeautifulSoup is a Python library that is being used to pull data out of HTML and XML files. This works with your favorite parser in order to provide idiomatic ways of navigating, searching, and modifying the parse tree. It is specially designed for quick and highly reliable data extraction.
Pandas is an open source library that allows us to perform data manipulation in Python web development. It is built on the Numpy package and its key data structure is called the DataFrame. DataFrames allows us to store and manipulate tabular data in rows of observations and columns of variables.
Tqdm is another python library that can promptly make your loops show a smart progress meter – all you have to do is just wrap any iterable with Tqdm(iterable).
Also Read
How To Use Python Lambda Functions With Examples
Demo: Scraping a Website
1. Look for the URL that you want to scrape
For the demonstration, we are going to scrape the webpage to extract the details of the Mobile phones. I’ve used a sample domain (www.example.com) to show you the process. Based on the steps explained in this tutorial, you can also try it with any other webpages you wish to scrap.
2. Analyze the Website
The data is commonly nested in tags. Analyze and inspect the page under which tag the data we want to scrape is nested. To inspect the page, just right click on the element and click on “Inspect”. A small inspect element box will be opened. You can able to see the raw code behind the site. Now you can find the tag of the details which you want to scrape.
You can find an arrow symbol on the top left of the console. If you click the arrow and then click on the product area, the code for the particular product area will be highlighted in the console tab.
The first thing that we should do is review and understand the structure of the HTML as it very significant to scrape the data from the website. There will be a lot of code on the website page and we need the code which contains our data. Learning the basics of HTML would be helpful in order to get familiar with the HTML tags.
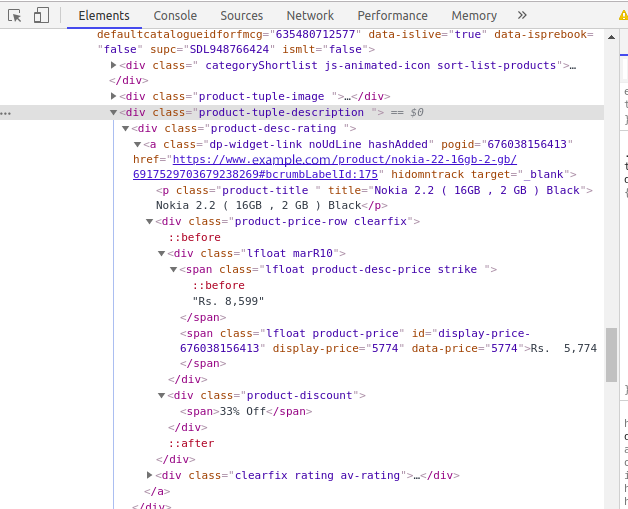
3. Find the data you want to extract
We are going to extract mobile phone data like product name, Actual price, Discounted price and so on. You can extract any kind of data you want. For that, We have to find the tag which contains our data.
Open the console by inspecting the area of the element. Click the arrow in the left corner and then click the product. You will now be able to see the particular code of the product which we clicked.
4. Write the Code
Now we have to find out the location of the data and the links. So let’s get started on the coding part.
- Create a file named scrap.py and open it in any editor of your choice.
- We will start writing the code by importing the libraries
We are going to use pip to install the following libraries. Pip is a package management system used to install and manage packages for python.
Import requests
To install the requests: pip install requests
From bs4 import BeautifulSoup
To install the BeautifulSoup: pip install beautifulsoup4
Import Pandas as pd
To install the Pandas: pip install pandas
From tqdm import tqdm, tnrange
To install the tqdm: pip install tqdm
- The first and primary process is to access the site in order to scrap the data.
- We have set the URL to the website and access the site which we going to scrap using with the requests library.
url = 'https://www.example.com/products/mobiles-mobile-phones?sort=plrty'
headers = {
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64)'
'AppleWebKit/537.36 (KHTML, like Gecko)'
'Chrome/64.0.3282.167 Safari/537.36'
}
result = requests.get(url, headers=headers,verify=True)
Print(result)
Output: <Response [200]>
If you see the above result, then you have accessed the website successfully.
5. Run the code and extract the data from the website
The HTTP 200 OK success status response code indicates that the request has succeeded. A 200 response is cacheable by default. If you want to learn more about the HTTP status codes, you can take a look here.
Now we are going to parse the HTML using the Beautifulsoup.
soup = BeautifulSoup(result.content, 'html.parser')
If we print the soup, then we will be able to see the whole HTML content of the website page. All we do now is to filter the section which contains our data. Therefore, we will extract the section tag from the soup.
section=soup.find("section", class_='js-section').find_all("div",{'class':'product-desc-rating})
Print(section)
which looks like,
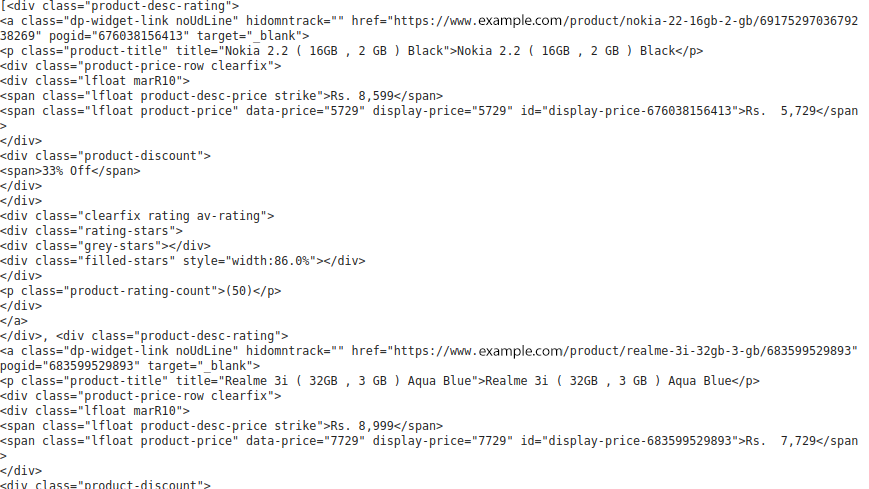
Now, we can extract the mobile phone details in the class ‘product-desc-rating’ of the div.
I have created a list for every column details of the mobile phone and append it to that list using for loop.
Products = [] url = [] Actual_Price = [] Discounted_Price = [] Discount = []
The product name is present under the p tag(paragraph tag) in the HTML and the product_url which is present under the anchor tag.
The HTML anchor tag defines a hyperlink that links one page to another page. It can create a hyperlink to another web page as well as files, locations, or any URL. The “href” attribute is the most important attribute of the HTML tag. and which links to the destination page or URL.
Then we are going to extract the actual price and discounted price which both present in the span tag.
The <span> tag is used to the grouping of inline-elements. And the <span> tag provides no visual change by itself.
And finally, we are going to extract the Offer percentage from the div tag.
The div tag is a block-level tag. It is a generic container tag. It is used to the group of various tags of HTML so that sections can be created and style can be applied to them.
for t in tqdm(section):
product_name = t.p.text
Products.append(product_name)
product_url = t.a['href']
url.append(product_url)
original_price = t.span.getText()
Actual_Price.append(original_price)
discounted_price = t.find('span', class_ = 'lfloat product-price').getText()
Discounted_Price.append(discounted_price)
try:
product_discount = t.find('div', class_ = 'product-discount')
Discount.append(product_discount.text)
except Exception as e:
product_discount = None
Discount.append(product_discount)
6. Store the data in the required Format
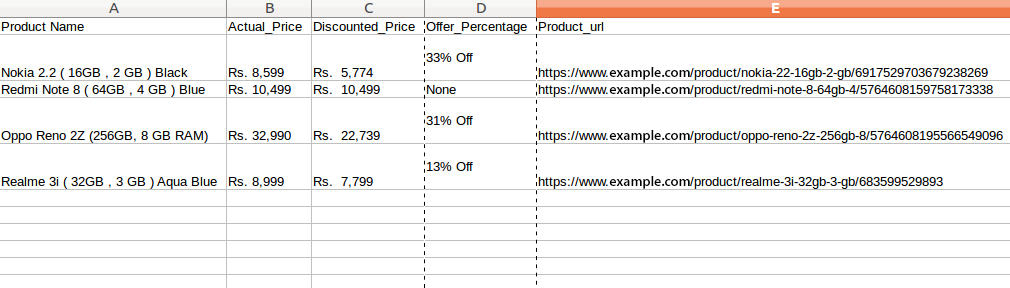
We have extracted the data. All we do now is to store the data in the file or to the database. You can store the data like the format you want. It depends upon your requirements. Here we will store the extracted data in the CSV(Comma Separated Value) format. To do this write the following code.
df = pd.DataFrame({'Product Name':Products,'Actual_Price':Actual_Price,'Discounted_Price':Discounted_Price,'Offer_Percentage':Discount,'Product_url':url})
df.to_csv(' products.csv', index=False, encoding='utf-8')
Now, you can easily scrap the data by running the script. To run the script use command python scrap.py. The data might vary according to the updates on the webpage.
I hope this guide was useful for you in performing Web Scraping using Python. I’d recommend you to practice this and use python for collecting data from web pages. Feel free to share your thoughts and doubts in the comment section.
Like what you just read? Want to continue reading on Python development? check out our blog.
Agira Technology is the leading choice as a Python development company! Get started with your Python project with our experts. Hire Python developers from Agira and get your brilliant Tech solutions to scale up the business.





